
NovelAI-embeddings模型訓練(教程)

這段時間問我怎么訓練模型的私信很多, 我這個教程與其說是教程, 更應該說是我自己訓練方法的一次記錄, 做模型教程的up主很多, 如果我的方法你覺得不合適, 那你可以嘗試其他up主的,畢竟這種東西沒有最好的, 只有最合適的.
我寫這個教程是想把一部分參數(shù)的意義說明白, 但是我不是ai方面的專業(yè)人士, 如有錯誤, 歡迎指正, 非常感謝.
首先你想開始訓練, 建議你擁有一張8G顯存或以上的顯卡, 沒有的話可以參考其他人發(fā)布的飛槳平臺云訓練.

基礎知識:
首先, 先來說一下基礎概念: 機器學習學習率, 損失函數(shù), 過擬合
(我本職不是ai相關的, 我是本職是數(shù)據(jù)分析師, 這里的只是我在閑暇時間自學的,如有錯誤,歡迎指正, 感謝感謝.)
損失函數(shù)(loss function):
是用來估量模型的預測值f(x)與真實值Y的不一致程度,?它是一個非負實值函數(shù), 通常使用L(Y, f(x))來表示, 損失函數(shù)越小, 模型的魯棒性就越好. 也可以簡單理解為與學習的目標圖像更加接近. 在實際使用中, 損失函數(shù)越低, 畫面效果一般較好, 但是由于不同素材本來就存在差異, 所以損失函數(shù)最后會穩(wěn)定在0.13-0.08之間, 如果你的損失函數(shù)長期穩(wěn)定在0.25-0.17之間, 你需要檢查你的原始素材是否存在較大差異, 比如不一致的服裝, 極大的畫風差異等.
如果你的損失函數(shù)長時間在0.3以上, 那我的建議是尋找前面損失值較低的存檔重新開始訓練, 可能是炸爐了.

Embedding模型學習率(Embedding Learning rate):
學習率LR表征了參數(shù)每次更新的幅度, 學習率過大, 前期收斂速度很快, 但是很快就會停止收斂, 因為學習率步長已經(jīng)大于模型最佳點與目前位置的距離. 學習率過小, 會出現(xiàn)收斂速度慢導致數(shù)據(jù)更新時間極長. 但是在完成模型學習后, 會得到更精細的模型.為了方便讀者更好的理解,我畫下了一個草圖(真的是隨手畫的, 我自己也知道很丑).


過擬合(Overfitting):
在制作模型的時候, 我們追求的肯定是損失函數(shù)的壓縮, 但是壓縮到一定程度就會出現(xiàn)一個問題, 一個模型專精程度越高, 泛化性越低.
比如你想訓練一個tag, 叫做樹葉(leaf)
你在處理訓練集的時候,放入了以下圖片:



你開始訓練完以后, 會出現(xiàn)一個情況, 就是你畫出來的所有樹葉, 都是帶鋸齒邊緣的, 因為在訓練集中存在鋸齒邊緣的樹葉, ai會認為樹葉都帶鋸齒,開始鉆牛角尖, 無論畫什么樹葉都會有鋸齒.
解決辦法是人工細化tag, 比如分別建立三個tag:maple leaves(楓葉),?Banyan leaves(榕樹葉),Mint leaf(薄荷葉), 這樣就能在一定程度上壓縮過擬合問題的發(fā)生.
實操
基礎知識講完了, 下面開始說具體步驟, 以webui為例.
第一步: 卸載models包離得vae文件
一般是直接找到vae文件, 在其前面加個1讓他無法被讀取.

第二步: 尋找訓練所需素材, 我一般是在pixiv收集素材的, 收集素材需要注意以下幾點:
1. 數(shù)量不用太多30-50張為佳, 質量比數(shù)量更重要
2. 要找清晰地, 單人的圖片, 沒有復雜背景效果最佳
3. 服裝必須相同, 否則服裝細節(jié)會模糊甚至錯誤
第三步:
創(chuàng)建空白Embedding
1. name欄填入你喜歡的名字
2. 選擇合適的向量token數(shù)
什么是向量token數(shù)?
Number of vectors per token(每個向量所擁有的特征數(shù)), 可以簡單得理解為特征數(shù)更多, 所獲得的的模型細節(jié)越多
(1)不同的向量token數(shù)有什么區(qū)別?
1-2: 只有簡單且模糊的人物輪廓, 無法使用單tag正常成像,
3-5: 有較清晰的人物圖像, 但單tag生成效果不好
6以上: 基本能實現(xiàn)單tag成像
(2)6以上有什么差距?
可以參考之前我之前發(fā)布的的專欄最早期的兩個模型是6-15token的, 然后token數(shù)每次都有一定提升, 每個模型大概提高5個點, 目前最先發(fā)布的阿羅娜我沒記錯的話是55-60這個區(qū)間的
?(3)向量token數(shù)是不是越大越好?
在6-25這個區(qū)間內越大越好, 但是在55以上之后就沒有太大的區(qū)別了(建議不要超過60), 較高的向量token會導致訓練所需的迭代次數(shù)提升, 降低訓練效率, 自己做取舍.

第四步:
圖像預處理
這一步很多up主建議自己剪, 但是我比較懶, 而且我覺得人工剪的意義不是很大, 我一般直接使用webui它自帶的預處理功能.
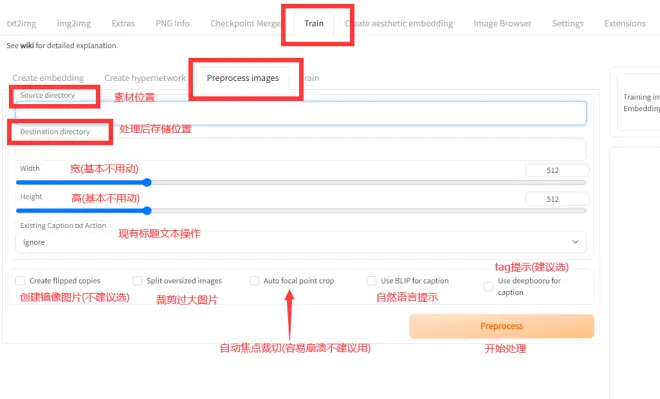

處理完之后會獲得如下圖像與文本

一個圖對應一個提取tag的txt文件
先看一下自動預處理出來的圖像, 有沒有什么部分缺失, 或者有沒有什么東西需要額外強調, 這時候就可以人工一1:1的比例切個512*512的圖片添加進去, 然后就可以開始訓練了.
第五步:
開始訓練

這里就要提到學習率問題:
開始的時候, 選擇默認的0.005學習率開始訓練, 大概在一萬兩千步左右( 具體情況看實際渲染圖, 最多的時候可能要到兩萬多步才清晰 )時, 訓練過程渲染圖會變得清晰, 且最近的幾個渲染圖都會很接近.
這時候可以進行第一次學習率壓縮, 點擊停止訓練, 然后調節(jié)Embedding Learning rate的數(shù)值, 我一般第二個學習率數(shù)值為0.0001, 然后重復上面的操作, 等待圖像清晰.
圖像再次清晰, 可以再次進行學習率壓縮, 我的習慣是直接在小數(shù)點后面加個0, 比如第二次是0.0001, 那第三次就是0.00001
但是, 學習率最小值不建議0.000001( 不用數(shù)了, 小數(shù)點后5個0 ),因為訓練圖像分辨率被壓縮為512*512, 部分精細的細節(jié)在預處理時已經(jīng)丟失了, 再降低學習率也沒有意義, 圖像細節(jié)不會有任何變化.
其他問題
(1)如果有些模型有些特殊細節(jié), 比如眼睛是星型瞳孔, 要怎么訓練?
多訓練一個針對性模型, 選擇畫風模板來操作, 只投入所需的眼睛圖片試試.
(2)為什么ai畫的眼睛會糊?
因為機器學習的目標就是降低損失函數(shù)值, 而損失函數(shù)值是根據(jù)特征判定的, 所以在迭代時, 模型會逐漸記錄起大量高頻特征. 但是不同畫師畫出來的眼睛是不同的, 即使同一個畫師在不同的畫里也會有差異, 所以模型會把大量特征拼湊起來, 組建出一個損失值更低的模型, 導致眼睛放大看會糊.
(3)如果我想要的角色是異色瞳, 但是瞳色左右顛倒了怎么辦?
不要使用圖像預處理的鏡像圖片功能, 就能減少異色瞳瞳色反轉的發(fā)生率, 生成的圖片瞳色反轉了, 可以嘗試用這張圖片生成鏡像圖片.
(4)為什么生成出來的圖片這么糊, 有沒有辦法提高畫質?
第一, 你可以提高迭代步數(shù), 一般拉到50-70之間就足夠了(我預渲染一般選擇50步);
第二, 你可以打開Highres. fix功能, 能提高圖像清晰度.

第三, 你可以訓練與你使用的Embedding配套的hypernetwork模型來補充細節(jié).
第四, 使用超分辨率重建軟件, 我用的是在github上下來的realesrgan-gui
鏈接為:https://github.com/TransparentLC/realesrgan-gui/
如果你上不了github也可以在我之前發(fā)布模型的那個百度云文件夾那里下載,鏈接為:
鏈接:https://pan.baidu.com/s/1MX0uRxxI5L2FTbQhhqYyiQ?pwd=0lx4?
提取碼:0lx4?
我使用的設定如下:


后記
ok, 差不多就這些, 有問題可以私信或者評論, 有空的時候會回復, 前提是不要太多, 太多把我干懵了可能就直接不看了.
